It’s been some time since I last blogged, largely because my focus has lain elsewhere in recent months writing long-form pieces for more traditional outlets. The most recent of these considers the question of trust in digital things, a topic spurred by the recent (and ongoing) scandal surrounding the Post Office Horizon computer system here in the UK which saw the false conviction for theft, fraud, and false accounting of hundreds of people. One of the things that came to the fore as a result of the scandal was the way that English law presumes the reliability of a computer system:
In effect, the ‘word’ of a computational system was considered to be of a higher evidential value than the opinion of legal professionals or the testimony of witnesses. This was not merely therefore a problem with digital evidence per se, but also the response to it. (McGuire and Renaud 2023: 453)
Michael Brian Schiffer is perhaps best-known (amongst archaeologists of a certain age in the UK at least), for his development of behavioural archaeology, which looked at the changing relationships between people and things as a response to the processual archaeology of Binford et al. (Schiffer 1976; 2010), and for his work on the formation processes of the archaeological record (Schiffer 1987). But Schiffer also has an extensive track record of work on archaeological (and behavioural) approaches to modern technologies and technological change (e.g., Schiffer 1992; 2011) which receives little attention in the digital archaeology arena, in part because despite his interest in a host of other electrical devices involved in knowledge creation (e.g., Schiffer 2013, 81ff) he has little to say about computers beyond observing their use in modelling and simulation or as an example of an aggregate technology constructed from multiple technologies and having a generalised functionality (Schiffer 2011, 167-171).
In his book The Archaeology of Science, Schiffer introduces the idea of the ‘discovery machine’. In applying such an apparatus,
From Cory Doctorow’s article, based on a 1936 original drawing by Wanda Gag for ‘Hansel and Gretel’ by the Brothers Grimm.
Cory Doctorow recently coined the term ‘enshittification’ in relation to digital platforms, which he defines as the way in which a platform starts by maximising benefits for its users and then, once they are locked in, switches attention to building profit for its shareholders at the expense of the users, before (often) entering a death-spiral (Doctorow 2023). He sees this applying to everything from Amazon, Facebook, Twitter, Tiktok, Reddit, Steam, and so on as they monetise their platforms and become less user-focused in a form of late-stage capitalism (Doctorow 2022; 2023). As he puts it:
… first, they are good to their users; then they abuse their users to make things better for their business customers; finally, they abuse those business customers to claw back all the value for themselves. Then, they die. (Doctorow 2023).
For instance, Harford (2023) points to the way that platforms like Amazon run at a loss for years in order to grow as fast as possible and make their users dependent upon the platform. Subsequent monetisation of a platform can be a delicate affair, as currently evidenced by the travails of Musk’s Twitter and the increasing volumes of people overcoming the inertia of the walled garden and moving to other free alternatives such as Mastodon, Bluesky, and, most recently, Threads. The vast amounts of personal data collected by commercial social media platforms strengthens their hold over their users, a key feature of advanced capitalism (e.g., Srnicek 2017), making it difficult for users to move elsewhere and also raising concerns about privacy and the uses to which such data may be put. Harford (2023) emphasises the undesirability of such monopolisation and the importance of building in interoperability between competing systems to allow users to switch away as a means of combatting enshittification.
Sometimes words or phrases are coined that seem very apposite in that they appear to capture the essence of a thing or concept and quickly become a shorthand for the phenomenon. ‘Digital twin’ is one such term, increasingly appearing in both popular and academic use with its meaning seemingly self-evident. The idea of a ‘digital twin’ carries connotations of a replica, a duplicate, a facsimile, the digital equivalent of a material entity, and conveniently summons up the impression of a virtual exact copy of something that exists in the real world.
For example, there was a great deal of publicity surrounding the latest 3D digital scan of the Titanic, created from 16 terabytes of data, 715,000 digital images and 4K video footage, and having a resolution capable of reading the serial number on one of the propellors. The term ‘digital twin’ was bandied around in the news coverage, and you’d be forgiven for thinking it simply means a high-resolution digital model of a physical object although the Ars Technica article hints at the possibility of using it in simulations to better understand the breakup and sinking of the ship. The impression gained is that a digital twin can simply be seen as a digital duplicate of a real-world object, and the casual use of the term would seem to imply little more than that. By this definition, photogrammetric models of excavated archaeological sections and surfaces would presumably qualify as digital twins of the original material encountered during the excavation, for instance.
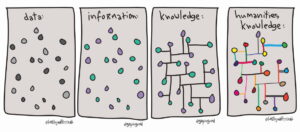
As archaeologists, we frequently celebrate the diversity and messiness of archaeological data: its literal fragmentary nature, inevitable incompleteness, variable recovery and capture, multiple temporalities, and so on. However, the tools and technologies that we have developed to use and reuse that data do their best to disguise or remove that messiness. Most of the tools and technologies that we employ in the recording, location, analysis, and reuse of our data generally try to reduce its complexity. Of course, there is nothing new in this – by definition, we always tend to simplify in order to make data analysable. However, those technical structures assume that data are static things, whereas they are in reality highly volatile as they move from their initial creation through to subsequent reuse, and as we select elements from the data to address the particular research question in hand. This data instability is something we often lose sight of.
The illusion of data as a fixed, stable resource is a commonplace – or, if not specifically acknowledged, we often treat data as if this were the case. In that sense, we subscribe to Latour’s perspective of data as “immutable mobiles” (Latour 1986; see also Leonelli 2020, 6). Data travels, but it is not essentially changed by those travels. For instance, books are immutable mobiles, their immutability acquired through the printing of multiple identical copies, their mobility through their portability and the availability of copies etc. (Latour 1986, 11). The immutability of data is seen to give it its evidential status, while its mobility enables it to be taken and reused by others elsewhere. This perspective underlies, implicitly at least, much of our approach to digital archaeological data and underpins the data infrastructures that we have created over the years.
Something most Twitter migrants experienced on first encounter with Mastodon was that it worked in a manner that was just different enough from Twitter to be somewhat disconcerting. This was nothing to do with tweets being called ‘toots’ (recently changed to posts following the influx of new users), or retweets being called ‘boosts’, or the absence of a direct equivalent to quote tweets. It had a lot to do with the federated model with its host of different instances serving different communities which meant that the first decision for any new user was which server to sign up with, and many struggled with this after the centralised models of Twitter (and Facebook, Instagram etc.) though older hands welcomed it as a reminder of how the internet used to be. It also had a lot to do with the feeds (be they Home, Local, or Federated) no longer being determined by algorithms that automatically promoted tweets but simply presenting posts in reverse chronological order. And it had to do with anti-harassment features that meant you could only find people on Mastodon if you knew their username and server, and the inability to search text other than hashtags. These were deliberately built into Mastodon, together with other, perhaps more obviously, useful features like Content Warnings on text and Sensitive Content on images, and simple alt-text handling for images.
A couple of interesting but unrelated articles around the subject of humanities digital data recently appeared: a guest post in The Scholarly Kitchen by Chris Houghton on data and digital humanities, and an Aeon essay by Claire Lemercier and Clair Zalc on historical data analysis.
Houghton’s article emphasises the benefits of mass digitisation and large-scale analysis in the context of the increasing availability of digital data resources provided through digital archives and others. According to Houghton, “The more databases and sources available to the scholar, the more power they will have to ask new questions, discover previously unknown trends, or simply strengthen an argument by adding more proof.” (Houghton 2022). The challenge he highlights is that although digital archives increasingly provide access to large bodies of data, the work entailed in exploring, refining, checking, and cleaning the data for subsequent analysis can be considerable.
An academic who runs a large digital humanities research group explained to me recently, “You can spend 80 percent of your time curating and cleaning the data, and another 80 percent of your time creating exploratory tools to understand it.” … the more data sources and data formats there are, the more complex this process becomes. (Houghton 2022).
Digital tools increasingly permeate our world, supporting, enhancing, or replacing many of our day-to-day activities in archaeology as elsewhere. Many of these devices lay claim to being ‘smart’, even intelligent, though more often than not this has more to do with sleight of hand and invisible software functionality than any actual intelligence. As Ian Bogost has recently observed, the key characteristic of these so-called smart devices is not intelligence so much as online connectivity, the realisation of which brings with it external surveillance and data-gathering (Bogost 2022). Such perceptions of ‘smartness’ might also point to a tendency for us to overestimate the capabilities of digital tools while at the same time minimise their influence.
In this light, I came across an interesting quotation from an anonymous archaeologist cited in Smiljana Antonijević’s book Amongst Digital Humanists: An Ethnographic Study of Digital Knowledge Production who said:
In archaeology, digital technologies such as GIS applications, laser scanning, or databases have been used for decades, and they are as common as a trowel or any other archaeological tool. (Antonijević 2016, 49).
Big Data has been described as revolutionary new scientific paradigm, one in which data-intensive approaches supersede more traditional scientific hypothesis testing. Conventional scientific practice entails the development of a research design with one or more falsifiable theories, followed by the collection of data which allows those theories to be tested and confirmed or rejected. In a Big Data world, the relationship between theory and data is reversed: data are collected first, and hypotheses arise from the subsequent analysis of that data (e.g., Smith and Cordes 2020, 102-3). Lohr described this as “listening to the data” to find correlations that appear to be linked to real world behaviours (2015, 104). Classically this is associated with Anderson’s (in)famous declaration of the “end of theory”:
With enough data, the numbers speak for themselves … Correlation supersedes causation, and science can advance even without coherent models, unified theories, or really any mechanistic explanation at all. (Anderson 2008).
Such an approach to investigation has traditionally been seen as questionable scientific practice, since patterns will always be found in even the most random data, if there’s enough data and powerful enough computers to process it.
Archaeological grey literature reports were primarily a response to the explosion of archaeological work from the 1970s (e.g. Thomas 1991) which generated a backlog which quickly outstripped the capacity of archaeologists, funders, and publishers to create traditional outputs, and it became accepted that the vast majority of fieldwork undertaken would never be published in any form other than as a client report or summary format. This in turn (and especially in academic circles) frequently raised concerns over the quality of the reports, as well as their accessibility: indeed, Cunliffe suggested that some reports were barely worth the paper they were printed on (cited in Ford 2010, 827). Elsewhere, it was argued that the schematisation of reports could make it easier to hide shortcomings and lead to lower standards (e.g. Andersson et al. 2010, 23). On the other hand, it was increasingly recognised that such reports had become the essential building blocks for archaeological knowledge to the extent that labelling them ‘grey’ was something of a misnomer (e.g. Evans 2015, sec 5), and the majority of archaeological interventions across Europe were being carried out within the framework of development-led archaeology rather than through the much smaller number of more traditional research excavations (e.g. Beck 2022, 3).